SpeechSSM يحل معضلة الصوت الطويل في الذكاء الاصطناعي
طورت الباحثة سيغين بارك، بجامعة KAIST الكورية، نموذجًا مبتكرًا يدعى SpeechSSM، يتميز بقدرته على توليد خطاب صوتي طبيعي يحل مشكلات الذكاء الاصطناعي.
النموذج الجديد، الذي نشر على منصة arXiv، ويرتقب تقديمه في مؤتمر ICML 2025، يمثل طفرة في مجال نماذج اللغة المنطوقة (SLMs)، التي تتجاوز الاعتماد على النصوص وتعمل مباشرة على الصوت البشري، مستفيدة من الخصائص الصوتية الفريدة للمتحدث.
مشكلة توليد المحتوى الصوتي الطويل
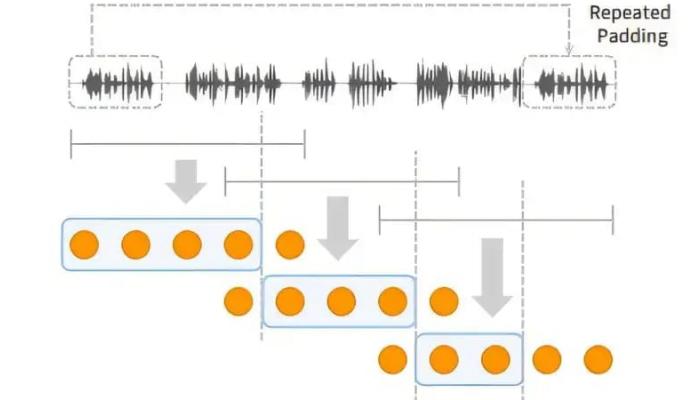
على عكس النماذج السابقة التي كانت تواجه صعوبة في الحفاظ على الاتساق الدلالي والشخصي خلال فترات طويلة من التوليد، يعالج SpeechSSM هذه المشكلة من خلال بنية هجينة تمزج بين:
- طبقات الانتباه (Attention Layers) التي تركز على المعلومات الحديثة،
- الطبقات التكرارية (Recurrent Layers) التي تحتفظ بالسياق العام للسرد.
ومتسق دون حدود زمنية، وهو ما يمثل قفزة نوعية مقارنة بالنماذج السابقة.
ويتيح هذا الهيكل للنموذج توليد قصص ومحتوى صوتي طويل دون فقدان التماسك أو زيادة مفرطة في استهلاك الذاكرة والمعالجة.
توليد سريع وجودة عالية
يعتمد SpeechSSM في مرحلة التوليد على نموذج صوتي غير توقعي (Non-Autoregressive) يعرف باسم SoundStorm، ما يسمح بإنتاج أقسام صوتية متعددة في وقت واحد، على عكس النماذج التقليدية التي تولد الأصوات حرفًا بحرف أو كلمة بكلمة، مما يقلل الزمن اللازم للتوليد ويحسن الجودة.
وبدلًا من الاعتماد على معيار PPL التقليدي، قدمت سيغين بارك أدوات تقييم جديدة مثل:
- SC-L لقياس التماسك الدلالي بمرور الوقت،
- N-MOS-T لتقييم طبيعة الصوت وواقعيته خلال فترات طويلة.
واعتمادًا على قاعدة بيانات جديدة باسم LibriSpeech-Long، أثبتت التجارب قدرة SpeechSSM على توليد محتوى صوتي يصل إلى 16 دقيقة من الحديث المتصل، مع الحفاظ على الشخصيات والأحداث والانسجام الكامل للنص، وهو ما فشلت فيه النماذج السابقة التي كانت تتكرر أو تفقد التركيز بسرعة.
قالت بارك: "هدفي كان تطوير نموذج لغوي منطوق يمكن استخدامه فعليًا من قبل البشر، وخاصة لتوليد محتوى صوتي طويل مثل البودكاست والكتب الصوتية والمساعدات الذكية".
وأكدت أن هذا النموذج سيحدث تطورًا كبيرًا في إنتاج المحتوى الصوتي عالي الجودة وفي تطبيقات الذكاء الاصطناعي التفاعلي.










